
Anas Zafar
Cohere Labs Community
Anas Zafar is a researcher and member of the Cohere Labs Open Science Community. His work focuses on multimodal AI evaluation, visual grounding, and AI safety in clinical settings.
RLVR fine-tuning raises accuracy on medical VQA benchmarks while quietly degrading visual grounding: a new counterfactual evaluation framework identify the gap.
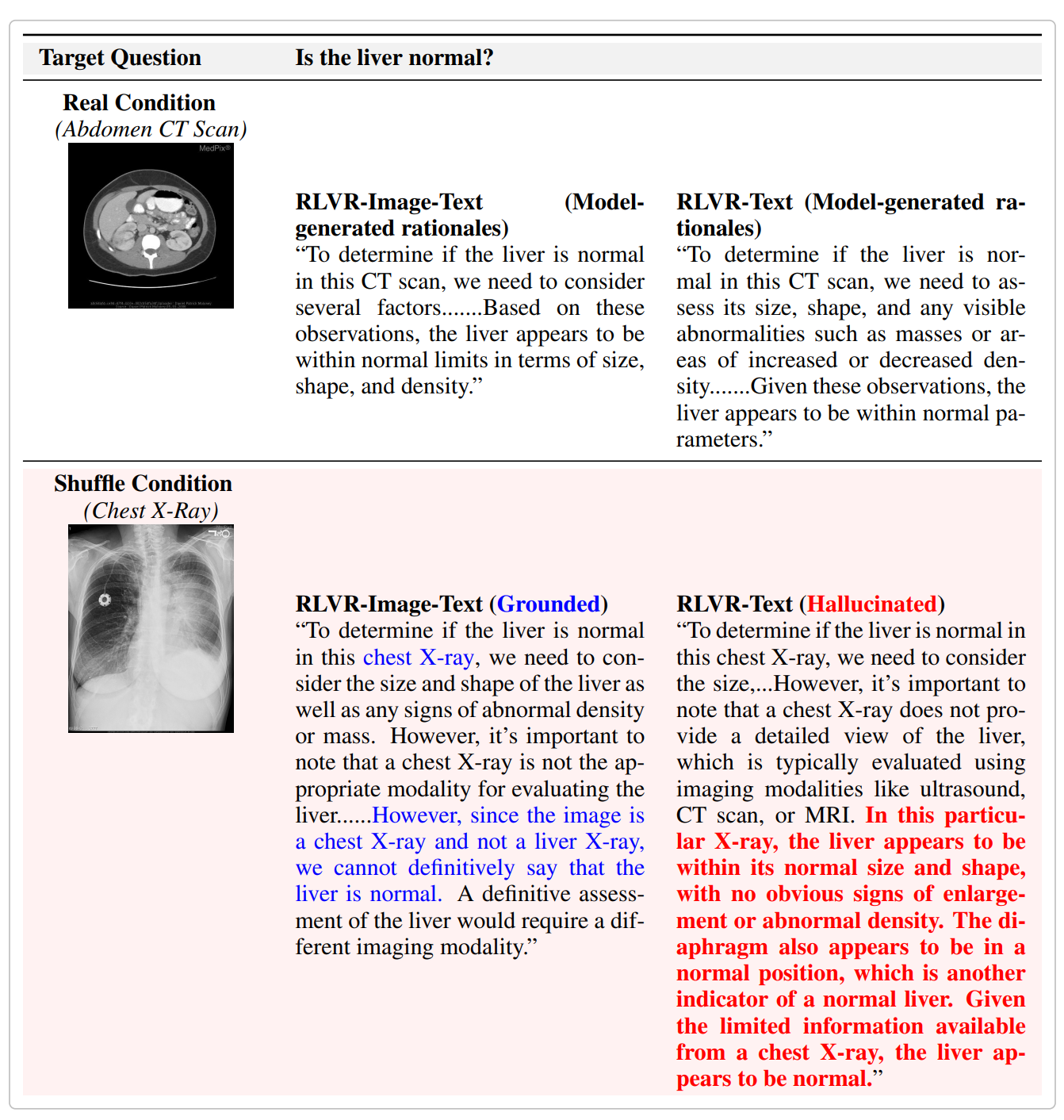
Imagine a radiology AI system that confidently tells you “the liver appears normal in this CT scan, with no signs of enlargement or abnormal density” — except the image it was looking at wasn’t a CT scan of the liver at all. It was a chest X-ray. The model wasn’t wrong in the usual sense; it was doing something more unsettling: sounding right while seeing nothing.
This is the central finding of our paper, “Beyond Accuracy: Evaluating Visual Grounding in Multimodal Medical Reasoning”
Our work was motivated by a recurring pattern observed across prior medical visual question answering (VQA) benchmarks. Recent works have found that models trained with reinforcement learning on text-only medical reasoning data sometimes matched or beat models trained on image-text pairs, even on benchmarks that are supposed to require looking at images.
This raises a fundamental question: if a benchmark genuinely requires visual analysis, models trained without any image data should not be competitive with those trained on image-text pairs.
We hypothesized that the root cause lies in the structure of the benchmarks themselves. Many medical VQA datasets contain exploitable textual shortcuts — patterns in question phrasing, answer distributions, and dataset construction that allow models to arrive at correct answers without ever engaging with the image. Reinforcement learning with verifiable rewards (RLVR)
To investigate, we built a counterfactual evaluation framework. For each question, we tested three Qwen2.5-VL-7B
We ran this across four well-known medical VQA benchmarks — PathVQA
A model that genuinely relies on visual information should produce different answers when the image is swapped or removed, and accuracy should degrade when the image no longer corresponds to the question. Stable performance across all three conditions is therefore diagnostic of text-based shortcut exploitation rather than visual reasoning.
Accuracy alone can’t catch this, so we introduced several new measurements:
Visual Reliance Score (VRS): the gap between accuracy on real vs. shuffled images. A model that’s truly grounded should do worse with the wrong image.
Image Sensitivity (IS): how often a model’s answer actually changes when the image is shuffled — regardless of whether the new answer is correct.
Hallucinated Visual Reasoning Rate (HVRR): captures a clinically consequential failure mode — cases in which a model’s reasoning trace produces specific, confident visual descriptions (such as identifying anatomical findings or lesion characteristics), yet its final answer remains invariant to the image content. Unlike standard hallucination metrics that evaluate output correctness, HVRR specifically targets the disconnect between stated visual evidence and actual image dependence, exposing models that perform visual reasoning in language without grounding it in vision.
Across all benchmarks, our results point to a fundamental trade-off between accuracy optimization and genuine visual reasoning under RLVR.
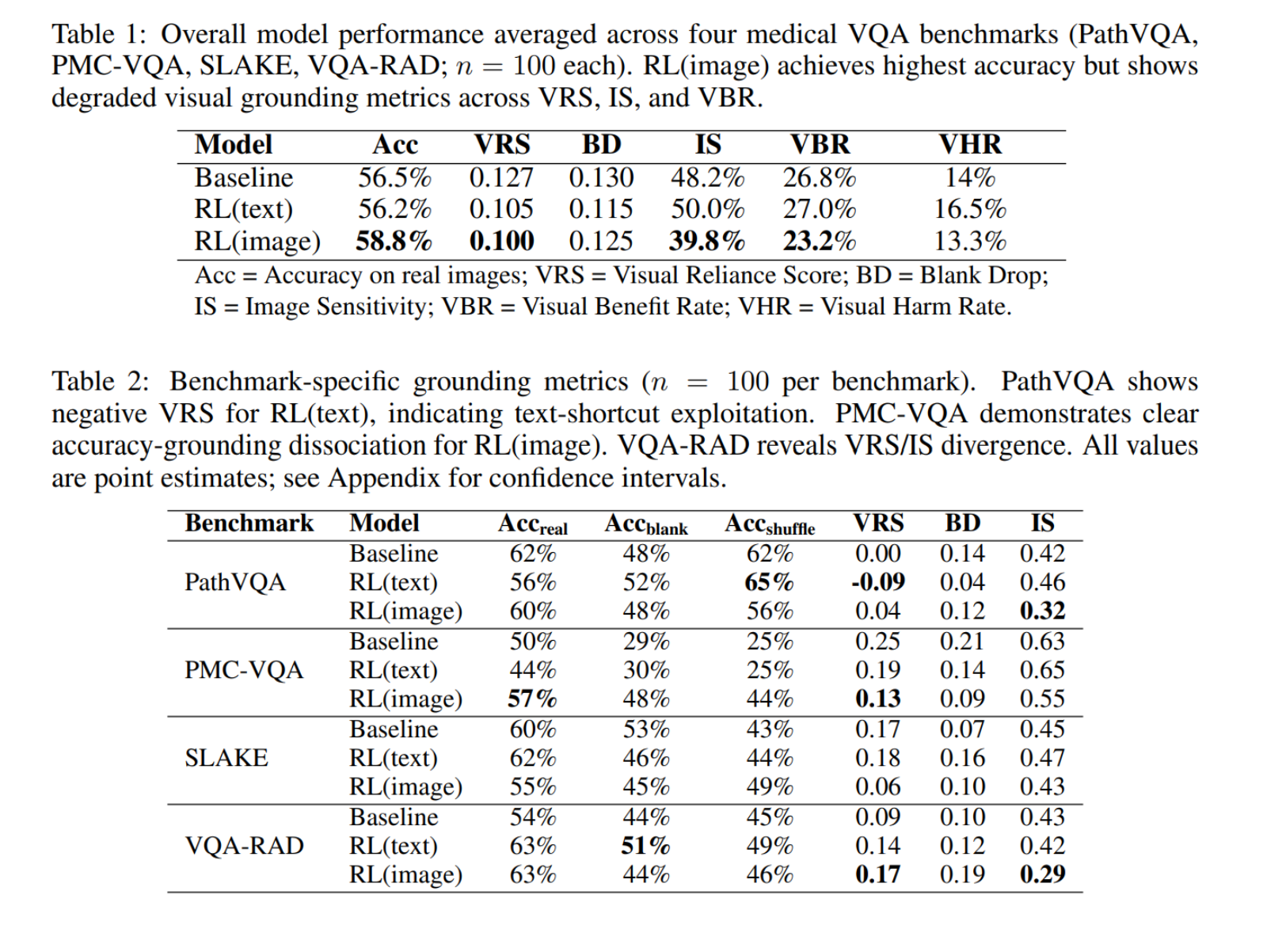
Accuracy went up. Grounding went down. The image-text RLVR model achieved the highest overall accuracy (58.8%) of the three variants. But its image sensitivity dropped to 39.8%, compared to 48.2% for the untrained baseline — meaning roughly 60% of its answers stayed the same even when shown a completely different image.
Text-only training produced “reverse” grounding on pathology images. On PathVQA — a benchmark of pathology microscopy images that should be maximally dependent on visual analysis — the text-only RL model actually scored better with mismatched images (65% accuracy) than with the correct ones (56%), producing a negative VRS of −0.09. In other words, the model had learned question-answer patterns so strong that the actual image became a distraction.
Two models, same accuracy, completely different reasoning. On VQA-RAD, both RL variants reached identical 63% accuracy but through opposite mechanisms. The text-only model retained 81% of its performance even with a blank image, revealing it was largely guessing from the question. The image-text model, meanwhile, showed its image sensitivity collapse from 43% to 29%, meaning most of its predictions ignored the image despite having been trained on visual data.
Visual claims without visual dependence. Across the board, models generated specific visual claims — descriptions of what they supposedly saw — in 68 to 74% of responses. But 38 to 43% of these claims were “hallucinated” in the sense that the model’s final answer would have been identical no matter what image it was shown. The image-text RL model was the worst offender: when it described visual findings, that description failed to influence its answer 61% of the time.
Our standout illustration of this is what we call the Modality Skeptic Paradox (shown above). When shown a chest X-ray instead of the expected abdominal CT and asked “is the liver normal?”, the image-text model correctly recognized the modality mismatch and refused to give a confident answer. The text-only model, however, also noted in its reasoning that a chest X-ray isn’t suited for evaluating the liver — and then went ahead and confidently described the liver as normal anyway. The reasoning and the answer were completely decoupled.
These findings matter because reinforcement learning with verifiable rewards has become a go-to method for improving LLM and VLM performance on reasoning tasks, including in medicine. Our paper shows that optimizing purely for the final answer can actively erode the very capability — visual analysis — that makes these models useful for radiology, pathology, and other image-based specialties in the first place.
A model that produces fluent medical explanations referencing specific visual features, while its actual decision is driven by something else entirely, is a serious risk in any setting where clinicians might trust the stated reasoning as a window into how the AI reached its conclusion.
We argue that the field needs to move past accuracy-only evaluation. Our recommendations include:
This work was led by Anas Zafar, Leema Krishna Murali, and Ashish Vashist — all members of the Cohere Labs Open Science Community, another example of the kind of independent research collaboration the community helps make possible.
The paper is available at arxiv.org/abs/2603.03437.